zstu.flot.moe
数据集的制作
后续处理数据时直接使用 public dataset in BigQuery,这里仅展示数据获取方法
使用 https://github.com/blockchain-etl/ethereum-etl/ 项目
运行环境:
CPU Model : Common KVM processor
CPU Cores : 3 @ 3399.996 MHz
CPU Cache : 16384 KB
AES-NI : ✗ Disabled
VM-x/AMD-V : ✗ Disabled
Total Disk : 96.8 GB (30.3 GB Used)
Total Mem : 3.8 GB (2.6 GB Used)
System uptime : 10 days, 10 hour 16 min
Load average : 1.84, 1.26, 0.76
OS : Ubuntu 22.04.4 LTS
Arch : x86_64 (64 Bit)
Kernel : 5.15.0-112-generic
TCP CC : cubic
Virtualization : KVM
IPv4/IPv6 : ✓ Online / ✓ Online
Organization : AS49770 Internetport Sweden AB
Location : Stockholm / SE
Region : Stockholm
安装Ethereum-ETL
进入Python3.8虚拟环境后执行
pip install ethereum-etl
获取 infura API
在 https://app.infura.io/ 获得API
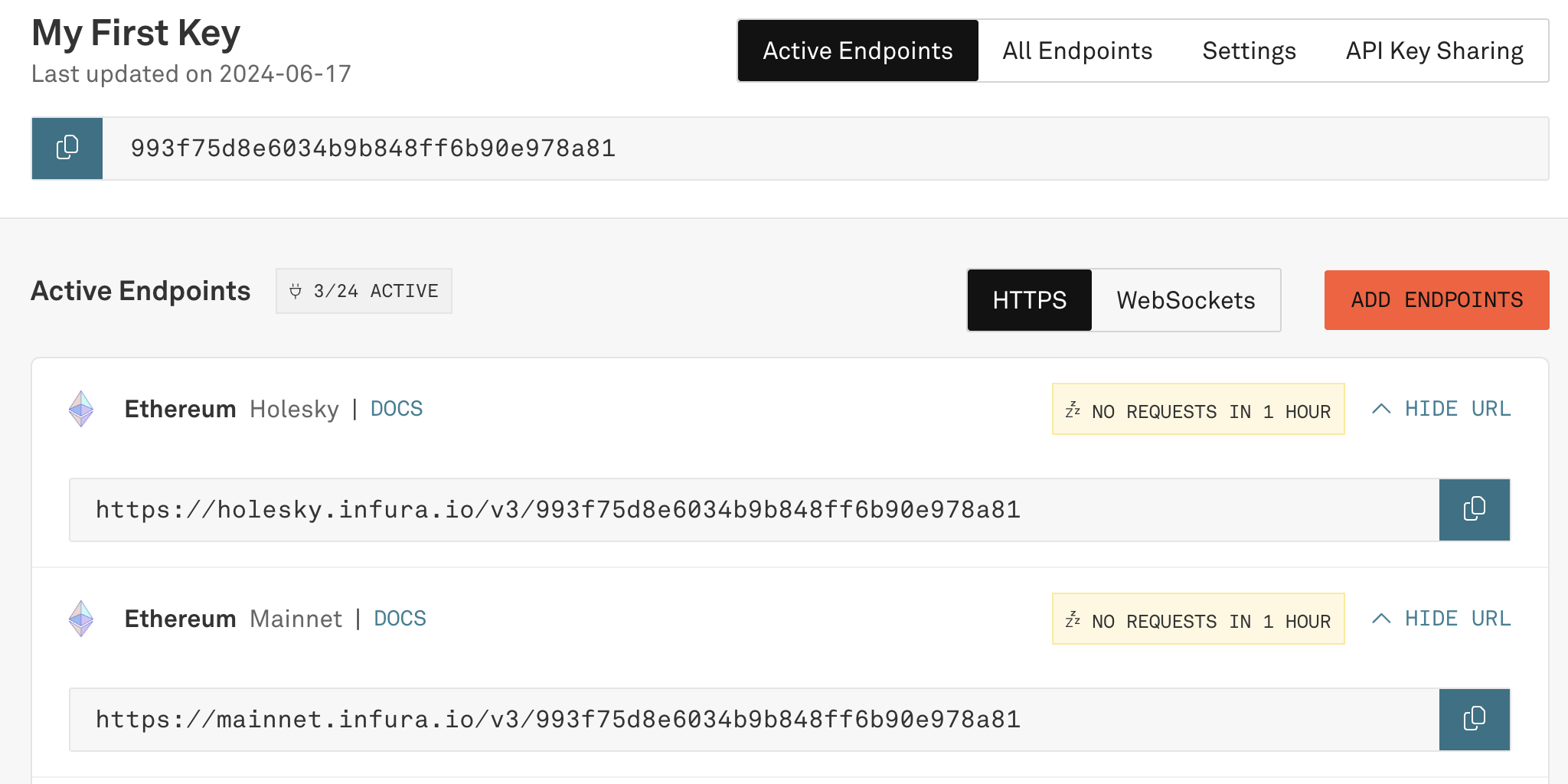
导出 blocks
ethereumetl export_blocks_and_transactions --start-block 0 --end-block 1000 \
--blocks-output blocks.csv --transactions-output transactions.csv \
--provider-uri https://mainnet.infura.io/v3/993f75d8e6034b9b848ff6b90e978a81


访问BigQuery API
设置认证环境变量
在GCP的 IAM和管理 -> 服务账号 中新增账号并创建秘钥
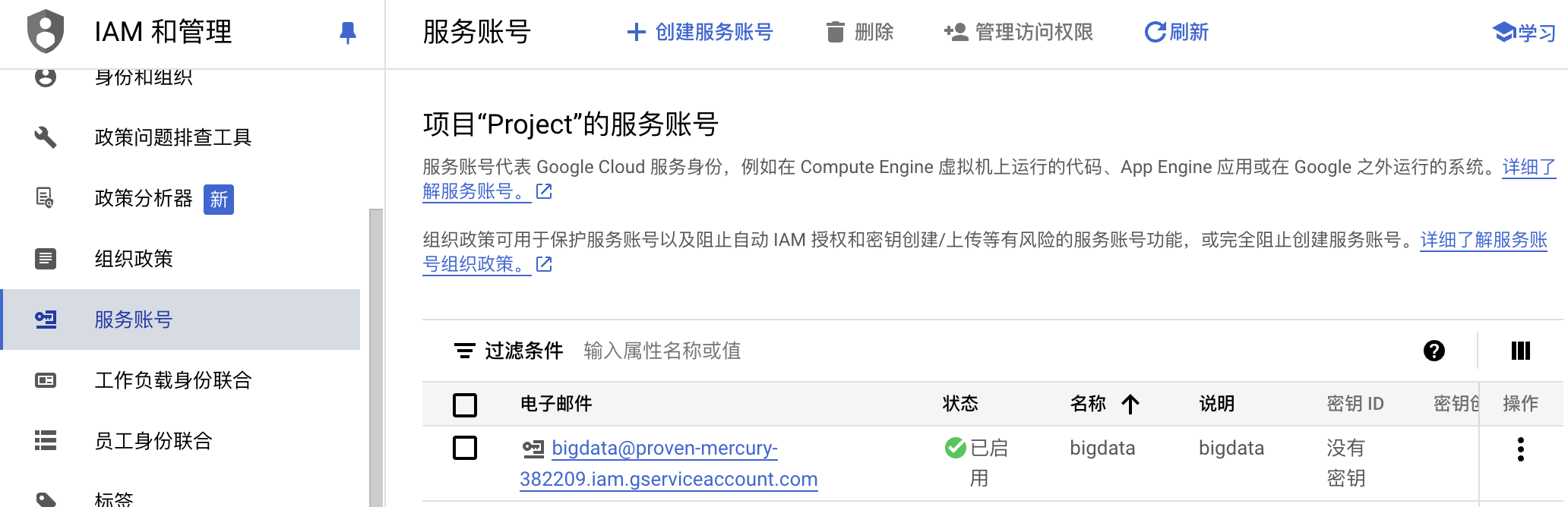
设置环境变量
export GOOGLE_APPLICATION_CREDENTIALS="/Users/nanmener/Downloads/proven-mercury-382209-efdbd404ef1a.json"
安装 google-cloud-bigquery 库
pip install google-cloud-bigquery
查询2022年9月15日的前200条交易数据
from google.cloud import bigquery
import pandas as pd
client = bigquery.Client()
query = """
SELECT *
FROM `bigquery-public-data.crypto_ethereum.transactions`
WHERE DATE(block_timestamp) = '2022-09-15'
LIMIT 200
"""
query_job = client.query(query)
results = query_job.result()
df = pd.DataFrame([dict(row) for row in results])
df.to_csv("ethereum_transactions_2022_09_15.csv", index=False)
print("Saved to ethereum_transactions_2022_09_15.csv")

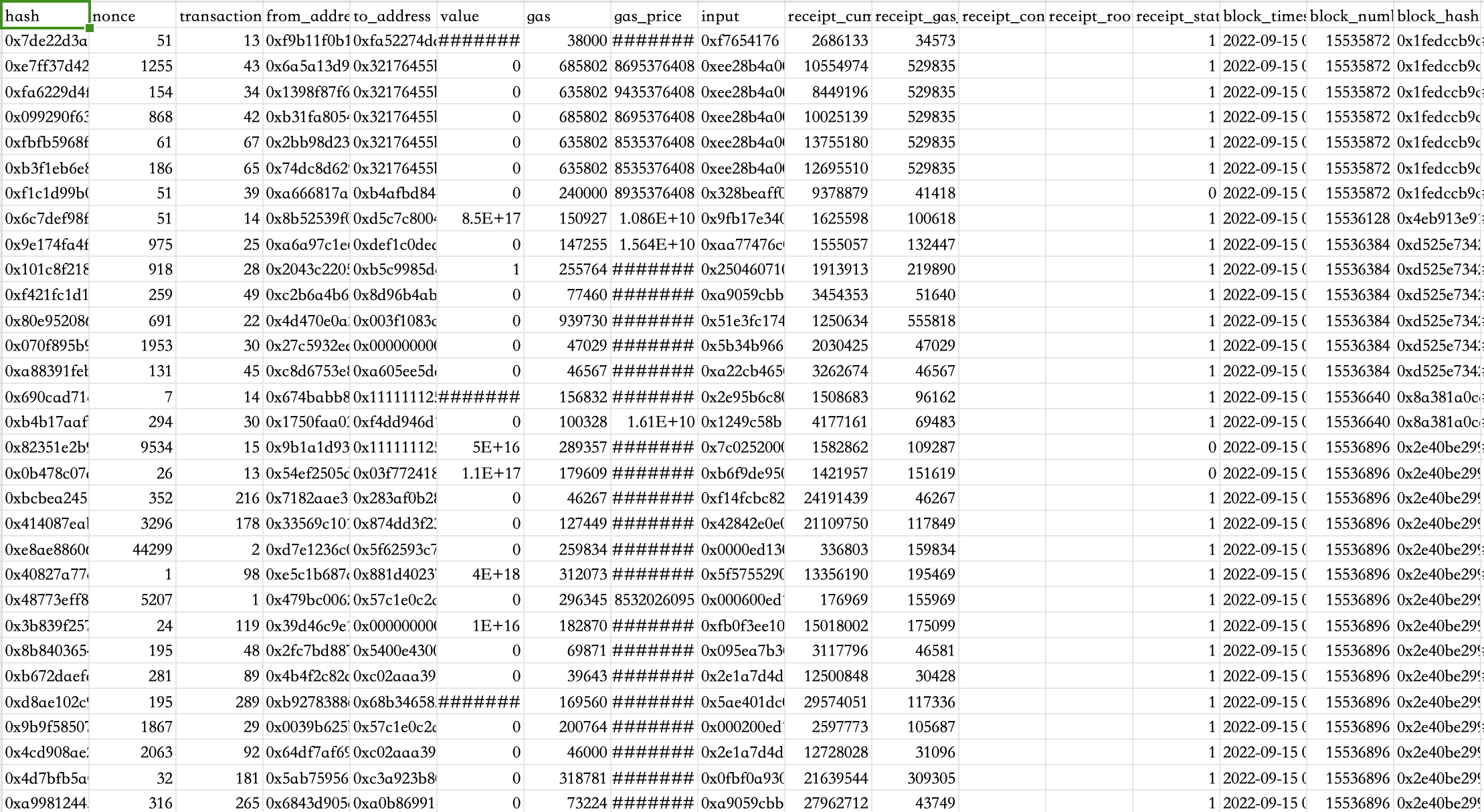
以上仅展示BigQuery API访问方法,可将数据下载到本地用于模型训练。由于数据规模较大,实际进行数据的分析处理时在云上进行(BigQuery Studio),相关代码已在论文中呈现。